![MongoDB replica sets replication internals r]()
![MongoDB replica sets replication internals r]() The MongoDB® replica set is a group of nodes with one set as the primary node, and all other nodes set as secondary nodes. Only the primary node accepts “write” operations, while other nodes can only serve “read” operations according to the read preferences defined. In this blog post, we’ll focus on some MongoDB replica set scenarios, and take a look at the internals.
The MongoDB® replica set is a group of nodes with one set as the primary node, and all other nodes set as secondary nodes. Only the primary node accepts “write” operations, while other nodes can only serve “read” operations according to the read preferences defined. In this blog post, we’ll focus on some MongoDB replica set scenarios, and take a look at the internals.
Example configuration
We will refer to a three node replica set that includes one primary node and two secondary nodes running as:
"members" : [
{
"_id" : 0,
"name" : "192.168.103.100:25001",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 3533,
"optime" : {
"ts" : Timestamp(1537800584, 1),
"t" : NumberLong(1)
},
"optimeDate" : ISODate("2018-09-24T14:49:44Z"),
"electionTime" : Timestamp(1537797392, 2),
"electionDate" : ISODate("2018-09-24T13:56:32Z"),
"configVersion" : 3,
"self" : true
},
{
"_id" : 1,
"name" : "192.168.103.100:25002",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 3063,
"optime" : {
"ts" : Timestamp(1537800584, 1),
"t" : NumberLong(1)
},
"optimeDurable" : {
"ts" : Timestamp(1537800584, 1),
"t" : NumberLong(1)
},
"optimeDate" : ISODate("2018-09-24T14:49:44Z"),
"optimeDurableDate" : ISODate("2018-09-24T14:49:44Z"),
"lastHeartbeat" : ISODate("2018-09-24T14:49:45.539Z"),
"lastHeartbeatRecv" : ISODate("2018-09-24T14:49:44.664Z"),
"pingMs" : NumberLong(0),
"syncingTo" : "192.168.103.100:25001",
"configVersion" : 3
},
{
"_id" : 2,
"name" : "192.168.103.100:25003",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 2979,
"optime" : {
"ts" : Timestamp(1537800584, 1),
"t" : NumberLong(1)
},
"optimeDurable" : {
"ts" : Timestamp(1537800584, 1),
"t" : NumberLong(1)
},
"optimeDate" : ISODate("2018-09-24T14:49:44Z"),
"optimeDurableDate" : ISODate("2018-09-24T14:49:44Z"),
"lastHeartbeat" : ISODate("2018-09-24T14:49:45.539Z"),
"lastHeartbeatRecv" : ISODate("2018-09-24T14:49:44.989Z"),
"pingMs" : NumberLong(0),
"syncingTo" : "192.168.103.100:25002",
"configVersion" : 3
}Here, the primary is running on port 25001, and the two secondaries are running on ports 25002 and 25003 on the same host.
Secondary nodes can only sync from Primary?
No, it’s not mandatory. Each secondary can replicate data from the primary or any other secondary to the node that is syncing. This term is also known as chaining, and by default, this is enabled.
In the above replica set, you can see that secondary node
"_id":2
is syncing from another secondary node
"_id":1
as
"syncingTo" : "192.168.103.100:25002"
This can also be found in the logs as here the parameter
chainingAllowed :true
is the default setting.
settings: { chainingAllowed: true, heartbeatIntervalMillis: 2000, heartbeatTimeoutSecs: 10, electionTimeoutMillis: 10000, catchUpTimeoutMillis: 60000, getLastErrorModes: {}, getLastErrorDefaults: { w: 1, wtimeout: 0 }, replicaSetId: ObjectId('5ba8ed10d4fddccfedeb7492') } }
Chaining?
That means that a secondary member node is able to replicate from another secondary member node instead of from the primary node. This helps to reduce the load from the primary. If the replication lag is not tolerable, then chaining could be disabled.
For more details about chaining and the steps to disable it please refer to my earlier blog post here.
Ok, then how does the secondary node select the source to sync from?
If Chaining is False
When chaining is explicitly set to be false, then the secondary node will sync from the primary node only or could be overridden temporarily.
If Chaining is True
Example for “unable to find a member to sync from” then, in the next attempt, finding a candidate to sync from
This can be found in the log like this. On receiving the message from rsBackgroundSync thread
could not find member to sync from
, the whole internal process restarts and finds a member to sync from i.e.
sync source candidate: 192.168.103.100:25001
, which means it is now syncing from node 192.168.103.100 running on port 25001.
2018-09-24T13:58:43.197+0000 I REPL [rsSync] transition to RECOVERING
2018-09-24T13:58:43.198+0000 I REPL [rsBackgroundSync] could not find member to sync from
2018-09-24T13:58:43.201+0000 I REPL [rsSync] transition to SECONDARY
2018-09-24T13:58:59.208+0000 I REPL [rsBackgroundSync] sync source candidate: 192.168.103.100:25001
- Once the sync source node is selected, SyncSourceResolver probes the sync source to confirm that it is able to fetch the oplogs.
- RollbackID is also fetched i.e. rbid after the first batch is returned by oplogfetcher.
- If all eligible sync sources are too fresh, such as during initial sync, then the syncSourceStatus Oplog start is missing and earliestOpTimeSeen will set a new minValid.
- This minValid is also set in the case of rollback and abrupt shutdown.
- If the node has a minValid entry then this is checked for the eligible sync source node.
Example showing the selection of a new sync source when the existing source is found to be invalid
Here, as the logs show, during sync the node chooses a new sync source. This is because it found the original sync source is not ahead, so not does not contain recent oplogs from which to sync.
2018-09-25T15:20:55.424+0000 I REPL [replication-1] Choosing new sync source because our current sync source, 192.168.103.100:25001, has an OpTime ({ ts: Timestamp 1537879296000|1, t: 4 }) which is not ahead of ours ({ ts: Timestamp 1537879296000|1, t: 4 }), it does not have a sync source, and it's not the primary (sync source does not know the primary)2018-09-25T15:20:55.425+0000 W REPL [rsBackgroundSync] Fetcher stopped querying remote oplog with error: InvalidSyncSource: sync source 192.168.103.100:25001 (config version: 3; last applied optime: { ts: Timestamp 1537879296000|1, t: 4 }; sync source index: -1; primary index: -1) is no longer valid
- If the secondary node is too far behind the eligible sync source node, then the node will enter maintenance node and then resync needs to be call manually.
- Once the sync source is chosen, BackgroundSync starts oplogFetcher.
Here is an example of fetching oplog from the “oplog.rs” collection, and checking for the greater than required timestamp.
2018-09-26T10:35:07.372+0000 I COMMAND [conn113] command local.oplog.rs command: getMore { getMore: 20830044306, collection: "oplog.rs", maxTimeMS: 5000, term: 7, lastKnownCommittedOpTime: { ts: Timestamp 1537955038000|1, t: 7 } } originatingCommand: { find: "oplog.rs", filter: { ts: { $gte: Timestamp 1537903865000|1 } }, tailable: true, oplogReplay: true, awaitData: true, maxTimeMS: 60000, term: 7, readConcern: { afterOpTime: { ts: Timestamp 1537903865000|1, t: 6 } } } planSummary: COLLSCAN cursorid:20830044306 keysExamined:0 docsExamined:0 numYields:1 nreturned:0 reslen:451 locks:{ Global: { acquireCount: { r: 6 } }, Database: { acquireCount: { r: 3 } }, oplog: { acquireCount: { r: 3 } } } protocol:op_command 3063398ms
When and what details replica set nodes communicate with each other?
At a regular interval, all the nodes communicate with each other to check the status of the primary node, check the status of the sync source, to get the oplogs and so on.
ReplicationCoordinator has ReplicaSetConfig that has a list of all the replica set nodes, and each node has a copy of it. This makes nodes aware of other nodes under same replica set.
This is how nodes communicate in more detail:
Heartbeats: This checks the status of other nodes i.e. alive or die
heartbeatInterval: Every node, at an interval of two seconds, sends the other nodes a heartbeat to make them aware that “yes I am alive!”
heartbeatTimeoutSecs: This is a timeout, and means that if the heartbeat is not returned in 10 seconds then that node is marked as inaccessible or simply die.
Every heartbeat is identified by these replica set details:
- replica set config version
- replica set name
- Sender host address
- id from the replicasetconfig
The source code could be referred to from here.
When the remote node receives the heartbeat, it processes this data and validates if the details are correct. It then prepares a ReplSetHeartbeatResponse, that includes:
- Name of the replica set, config version, and optime details
- Details about primary node as per the receiving node.
- Sync source details and state of receiving node
This heartbeat data is processed, and if primary details are found then the election gets postponed.
TopologyCoordinator checks for the heartbeat data and confirms if the node is OK or NOT. If the node is OK then no action is taken. Otherwise it needs to be reconfigured or else initiate a priority takeover based on the config.
Response from oplog fetcher
To get the oplogs from the sync source, nodes communicate with each other. This oplog fetcher fetches oplogs through “find” and “getMore”. This will only affect the downstream node that gets metadata from its sync source to update its view from the replica set.
OplogQueryMetadata only comes with OplogFetcher responses
OplogQueryMetadata comes with OplogFetcher response and ReplSetMetadata comes with all the replica set details including configversion and replication commands.
Communicate to update Position commands:
This is to get an update for replication progress. ReplicationCoordinatorExternalState creates SyncSourceFeedback sends replSetUpdatePosition commands.
It includes Oplog details, Replicaset config version, and replica set metadata.
If a new node is added to the existing replica set, how will that node get the data?
If a new node is added to the existing replica set then the “initial sync” process takes place. This initial sync can be done in two ways:
- Just add the new node to the replicaset and let initial sync threads restore the data. Then it syncs from the oplogs until it reaches the secondary state.
- Copy the data from the recent data directory to the node, and restart this new node. Then it will also sync from the oplogs until it reaches the secondary state.
This is how it works internally
When “initial sync” or “rsync” is called by ReplicationCoordinator then the node goes to “STARTUP2” state, and this initial sync is done in DataReplicator
- A sync source is selected to get the data from, then it drops all the databases except the local database, and oplogs are recreated.
- DatabasesCloner asks syncsource for a list of the databases, and for each database it creates DatabaseCloner.
- For each DatabaseCloner it creates CollectionCloner to clone the collections
- This CollectionCloner calls ListIndexes on the syncsource and creates a CollectionBulkLoader for parallel index creation while data cloning
- The node also checks for the sync source rollback id. If rollback occurred, then it restarts the initial sync. Otherwise, datareplicator is done with its work and then replicationCoordinator assumes the role for ongoing replication.
Example for the “initial sync” :
Here node enters
"STARTUP2"- "transition to STARTUP2"
Then sync source gets selected and drops all the databases except the local database. Next, replication oplog is created and CollectionCloner is called.
Local database not dropped: because every node has its own “local” database with its own and other nodes’ information, based on itself, this database is not replicated to other nodes.
2018-09-26T17:57:09.571+0000 I REPL [ReplicationExecutor] transition to STARTUP2
2018-09-26T17:57:14.589+0000 I REPL [replication-1] sync source candidate: 192.168.103.100:25003
2018-09-26T17:57:14.590+0000 I STORAGE [replication-1] dropAllDatabasesExceptLocal 1
2018-09-26T17:57:14.592+0000 I REPL [replication-1] creating replication oplog of size: 990MB... 2018-09-26T17:57:14.633+0000 I REPL [replication-0] CollectionCloner::start called, on ns:admin.system.version
Finished fetching all the oplogs, and finishing up initial sync.
2018-09-26T17:57:15.685+0000 I REPL [replication-0] Finished fetching oplog during initial sync: CallbackCanceled: Callback canceled. Last fetched optime and hash: { ts: Timestamp 1537984626000|1, t: 9 }[-1139925876765058240]
2018-09-26T17:57:15.685+0000 I REPL [replication-0] Initial sync attempt finishing up.
What are oplogs and where do these reside?
oplogs stands for “operation logs”. We have used this term so many times in this blog post as these are the mandatory logs for the replica set. These operations are in the capped collection called “oplog.rs” that resides in “local” database.
Below, this is how oplogs are stored in the collection “oplog.rs” that includes details for timestamp, operations, namespace, output.
rplint:PRIMARY> use local
rplint:PRIMARY> show collections
oplog.rs
rplint:PRIMARY> db.oplog.rs.findOne()
{
"ts" : Timestamp(1537797392, 1),
"h" : NumberLong("-169301588285533642"),
"v" : 2,
"op" : "n",
"ns" : "",
"o" : {
"msg" : "initiating set"
}
}It consists of rolling update operations coming to the database. Then these oplogs replicate to the secondary node(s) to maintain the high availability of the data in case of failover.
When the replica MongoDB instance starts, it creates an oplog ocdefault size. For Wired tiger, the default size is 5% of disk space, with a lower bound size of 990MB. So here in the example it creates 990MB of data. If you’d like to learn more about oplog size then please refer here
2018-09-26T17:57:14.592+0000 I REPL [replication-1] creating replication oplog of size: 990MB...
What if the same oplog is applied multiple times, will that not lead to inconsistent data?
Fortunately, oplogs are Idempotent that means the value will remain unchanged, or will provide the same output, even when applied multiple times.
Let’s check an example:
For the $inc operator that will increment the value by 1 for the filed “item”, if this oplog is applied multiple times then the result might lead to an inconsistent record if this is not Idempotent. However, rather than increasing the item value multiple times, it is actually applied only once.
rplint:PRIMARY> use db1
//inserting one document
rplint:PRIMARY> db.col1.insert({item:1, name:"abc"})
//updating document by incrementing item value with 1
rplint:PRIMARY> db.col1.update({name:"abc"},{$inc:{item:1}})
//updated value is now item:2
rplint:PRIMARY> db.col1.find()
{ "_id" : ObjectId("5babd57cce2ef78096ac8e16"), "item" : 2, "name" : "abc" }This is how these operations are stored in oplog, here this $inc value is stored in oplog as $set
rplint:PRIMARY> db.oplog.rs.find({ns:"db1.col1"})
//insert operation
{ "ts" : Timestamp(1537987964, 2), "t" : NumberLong(9), "h" : NumberLong("8083740413874479202"), "v" : 2, "op" : "i", "ns" : "db1.col1", "o" : { "_id" : ObjectId("5babd57cce2ef78096ac8e16"), "item" : 1, "name" : "abc" } }
//$inc operation is changed as ""$set" : { "item" : 2"
{ "ts" : Timestamp(1537988022, 1), "t" : NumberLong(9), "h" : NumberLong("-1432987813358665721"), "v" : 2, "op" : "u", "ns" : "db1.col1", "o2" : { "_id" : ObjectId("5babd57cce2ef78096ac8e16") }, "o" : { "$set" : { "item" : 2 } } }That means that however many times it is applied, it will generate the same results, so no inconsistent data!
I hope this blog post helps you to understand multiple scenarios for MongoDB replica sets, and how data replicates to the nodes.



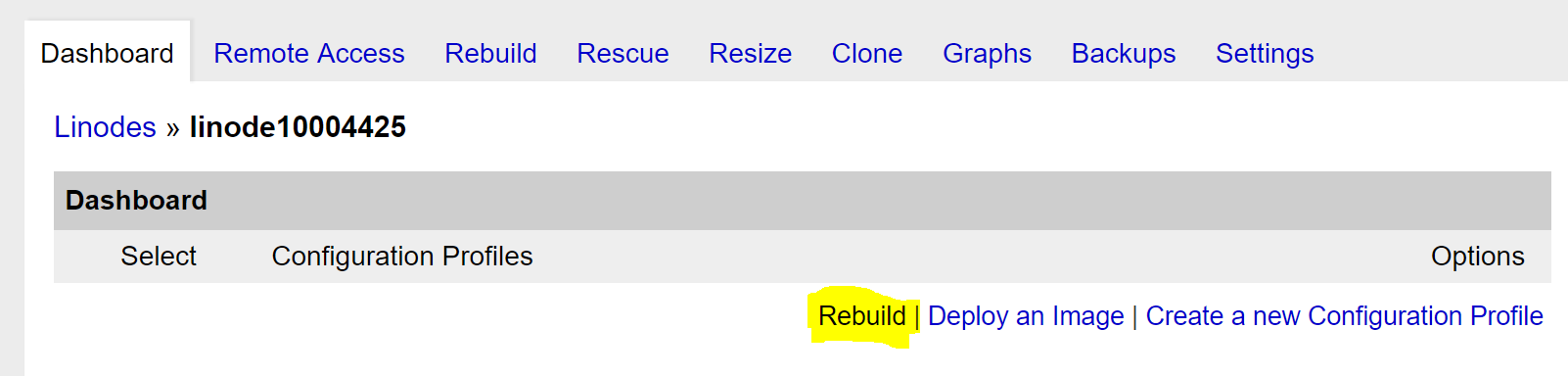

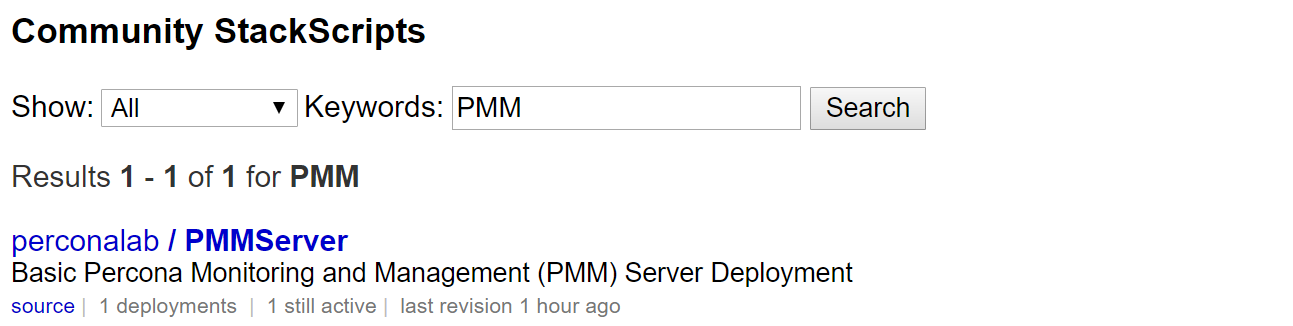
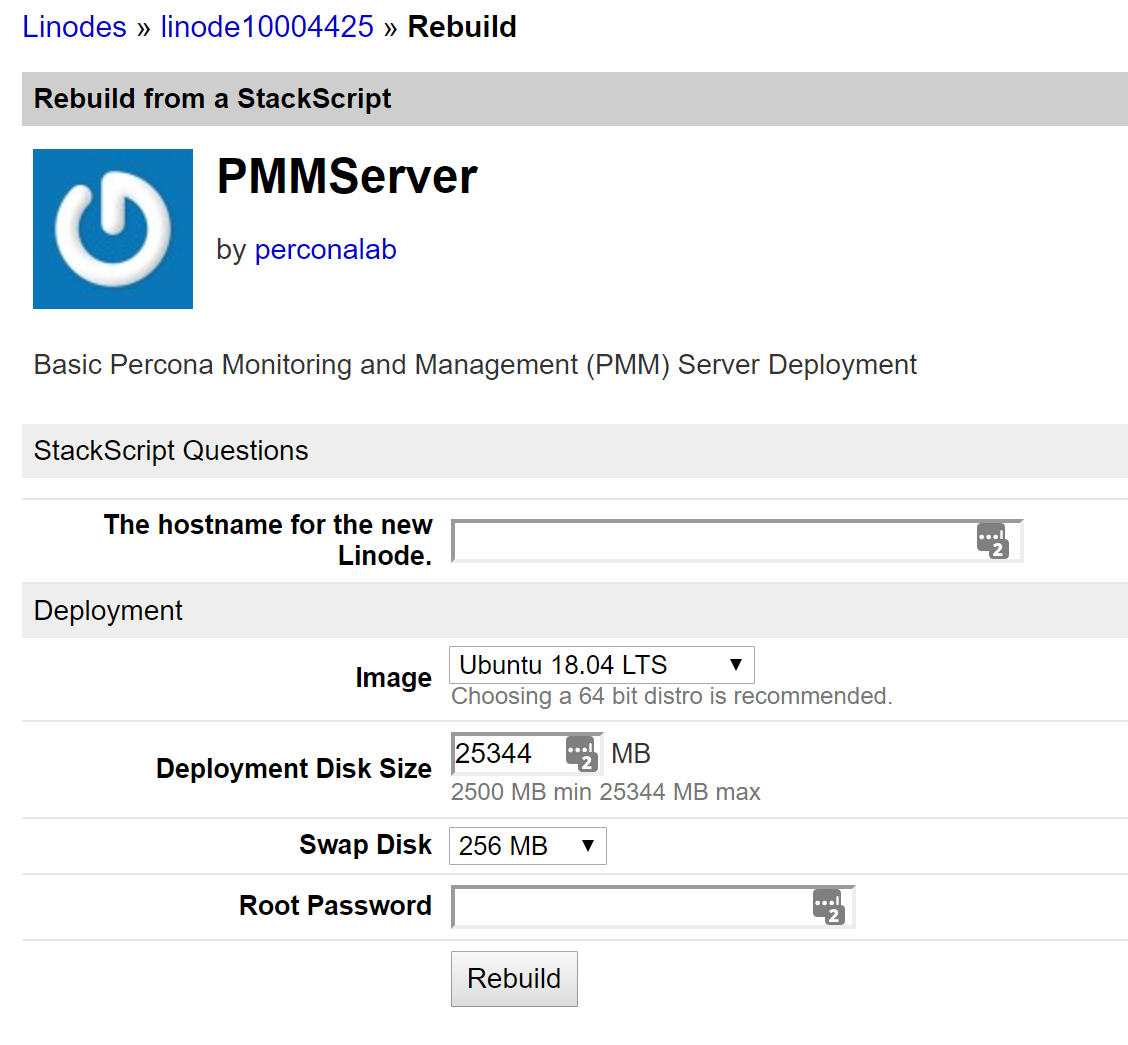
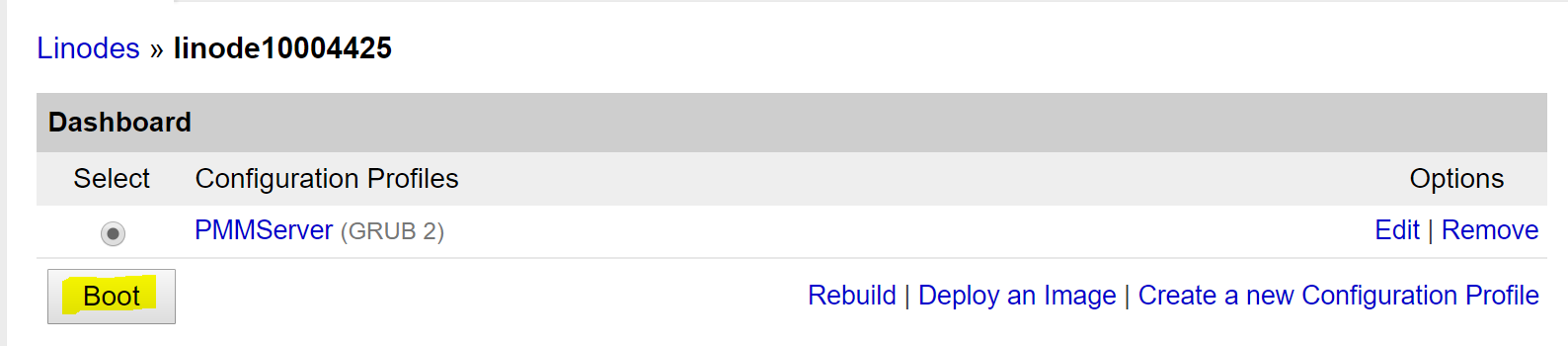















 Some time ago, a customer had a performance issue with an internal process. He was comparing, finding, and reporting the rows that were different between two tables. This is simple if you use a LEFT JOIN and an
Some time ago, a customer had a performance issue with an internal process. He was comparing, finding, and reporting the rows that were different between two tables. This is simple if you use a LEFT JOIN and an 
 When deciding on your backup strategy, one of the key components for
When deciding on your backup strategy, one of the key components for 
 In this blog post, we will learn what MongoDB chained replication is, why you might choose to disable it, and the steps you need to take to do so.
In this blog post, we will learn what MongoDB chained replication is, why you might choose to disable it, and the steps you need to take to do so.




 The release of MySQL 8.0 has brought a lot of bold implementations that touched on things that have been avoided before, such as added support for common table expressions and window functions. Another example is the change in how AUTO_INCREMENT (autoinc) sequences are persisted, and thus replicated.
The release of MySQL 8.0 has brought a lot of bold implementations that touched on things that have been avoided before, such as added support for common table expressions and window functions. Another example is the change in how AUTO_INCREMENT (autoinc) sequences are persisted, and thus replicated. Trey Raymond is a Sr. Database Engineer for
Trey Raymond is a Sr. Database Engineer for  Fernando is a Senior Support Engineer with Percona. Fernando’s work experience includes the architecture, deployment and maintenance of IT infrastructures based on Linux, open source software and a layer of server virtualization. He’s now focusing on the universe of MySQL, MongoDB and PostgreSQL with a particular interest in understanding the intricacies of database systems, and contributes regularly to this blog. You can read
Fernando is a Senior Support Engineer with Percona. Fernando’s work experience includes the architecture, deployment and maintenance of IT infrastructures based on Linux, open source software and a layer of server virtualization. He’s now focusing on the universe of MySQL, MongoDB and PostgreSQL with a particular interest in understanding the intricacies of database systems, and contributes regularly to this blog. You can read 
 The MongoDB® replica set is a group of nodes with one set as the primary node, and all other nodes set as secondary nodes. Only the primary node accepts “write” operations, while other nodes can only serve “read” operations according to the read preferences defined. In this blog post, we’ll focus on some MongoDB replica set scenarios, and take a look at the internals.
The MongoDB® replica set is a group of nodes with one set as the primary node, and all other nodes set as secondary nodes. Only the primary node accepts “write” operations, while other nodes can only serve “read” operations according to the read preferences defined. In this blog post, we’ll focus on some MongoDB replica set scenarios, and take a look at the internals.
 Probably not well known but quite an important optimization was introduced in MySQL 5.6 –
Probably not well known but quite an important optimization was introduced in MySQL 5.6 – 


 pt-query-digest
pt-query-digest

 We have many backup methods to backup a MongoDB database using native mongodump or external tools. However, in this article, we’ll take a look at the backup tools offered by Percona, keeping in mind the restoration scenarios for MongoDB replicaSet and Sharded Cluster environments. We’ll explore how and when to use the tool
We have many backup methods to backup a MongoDB database using native mongodump or external tools. However, in this article, we’ll take a look at the backup tools offered by Percona, keeping in mind the restoration scenarios for MongoDB replicaSet and Sharded Cluster environments. We’ll explore how and when to use the tool